We use closed-loop game environments to demonstrate and study how biological neurons learn, adapt, and perform computation in real time.
Objective:
We designed the Dino task as a one-dimensional sensorimotor decision-making paradigm to test whether biological neurons could perform time-sensitive action selection in a minimal closed-loop environment. The task reduced behavior to a binary output, jump or no jump, allowing us to isolate whether neurons could compute the correct response from a continuously varying input signal.
Setup:
In this setup, the game state was parameterized by a single task-relevant variable: the distance between the dinosaur and the approaching cactus. That variable was encoded as a rate-coded input stimulus and delivered to the neuronal system through the interface. The system was required to map this one-dimensional input stream onto a binary behavioral output, triggering a jump at the appropriate time to avoid collision. Unlike more complex adaptive tasks, no explicit feedback or reward signal was provided during gameplay, making this a feedforward decision task rather than a reinforcement-based learning paradigm.
Results and Observations:
The neuronal system was able to generate appropriately timed responses from the encoded distance signal alone, producing jump decisions with high reliability. Despite the absence of explicit feedback, the neurons achieved greater than 90% accuracy on the task. These results indicate that biological neurons were able to perform real-time computation and action selection in a constrained one-dimensional environment, demonstrating robust task-relevant response generation even in the absence of reinforcement.
Objective:
We designed the Asteroid Dodger task as a closed-loop one-dimensional visuomotor control paradigm to test whether biological neurons could solve a more demanding continuous decision-making problem than binary action selection. Unlike the Dino task, which reduced behavior to a single time-locked jump decision, this task required neurons to continuously control the lateral position of a rocket in order to avoid incoming asteroids. The objective was to determine whether neurons could not only compute task-relevant motor output in real time, but also improve performance under reinforcement in a dynamic environment.
Setup:
The Asteroid Dodger task was implemented as a closed-loop one-dimensional control problem in which biological neurons had to continuously steer a rocket left or right to avoid descending asteroids. The sensory state of the task was encoded through four stimulation channels, with asteroid position mapped onto one of four spatial strips and asteroid proximity encoded through rate coding, such that stimulation frequency increased as the asteroid approached the rocket. Neural activity was recorded from candidate motor regions partitioned into left and right ensembles, and motor output was decoded from the spike-count difference between those two populations. That decoded difference was then transformed into continuous ship movement, allowing the neuronal system to control the rocket’s horizontal position in closed loop.
In contrast to the Dino paradigm, this task incorporated explicit feedback. Successful asteroid avoidance triggered reward stimulation, whereas collision triggered a punishment protocol followed by a reset of the task state. This made the Asteroid Dodger paradigm reinforcement-based rather than purely feedforward, allowing us to test whether neuronal activity could be shaped through closed-loop interaction with task outcomes. The design therefore combined continuous sensory encoding, population-based motor decoding, and reward/punishment feedback within a single adaptive control framework.
Results and Observations:
Performance improvement emerged progressively rather than instantaneously, consistent with a learning-dependent adaptation process. Learning onset was observed after approximately 6 minutes, and performance peaked at approximately 12 minutes, where the system reached a dodge rate of 86.5%. This improvement was not present in the control condition, which received the same sensory input but no feedback and failed to develop task proficiency over time. Quantitatively, the feedback-trained condition performed roughly twice as well as the no-feedback control.
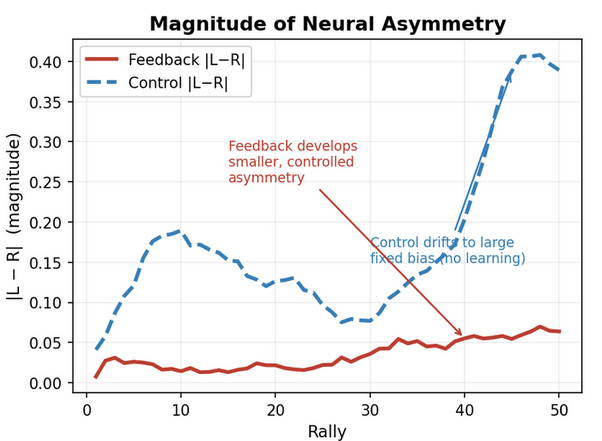
The asymmetry metric shown above corresponds to the decoded left-right spike-count difference that drove continuous ship displacement in the Asteroid Dodger task. Because movement was computed directly from this differential motor signal, stable asymmetry is a proxy for the emergence of task-relevant neural control. In the feedback-trained condition, this signal converged toward a persistent, interpretable directional bias, whereas the no-feedback control exhibited drift without comparable stabilization. Given that both conditions shared the same sensory structure, the separation between the two traces suggests that closed-loop reinforcement shaped the neural dynamics into a more behaviorally useful control signal.
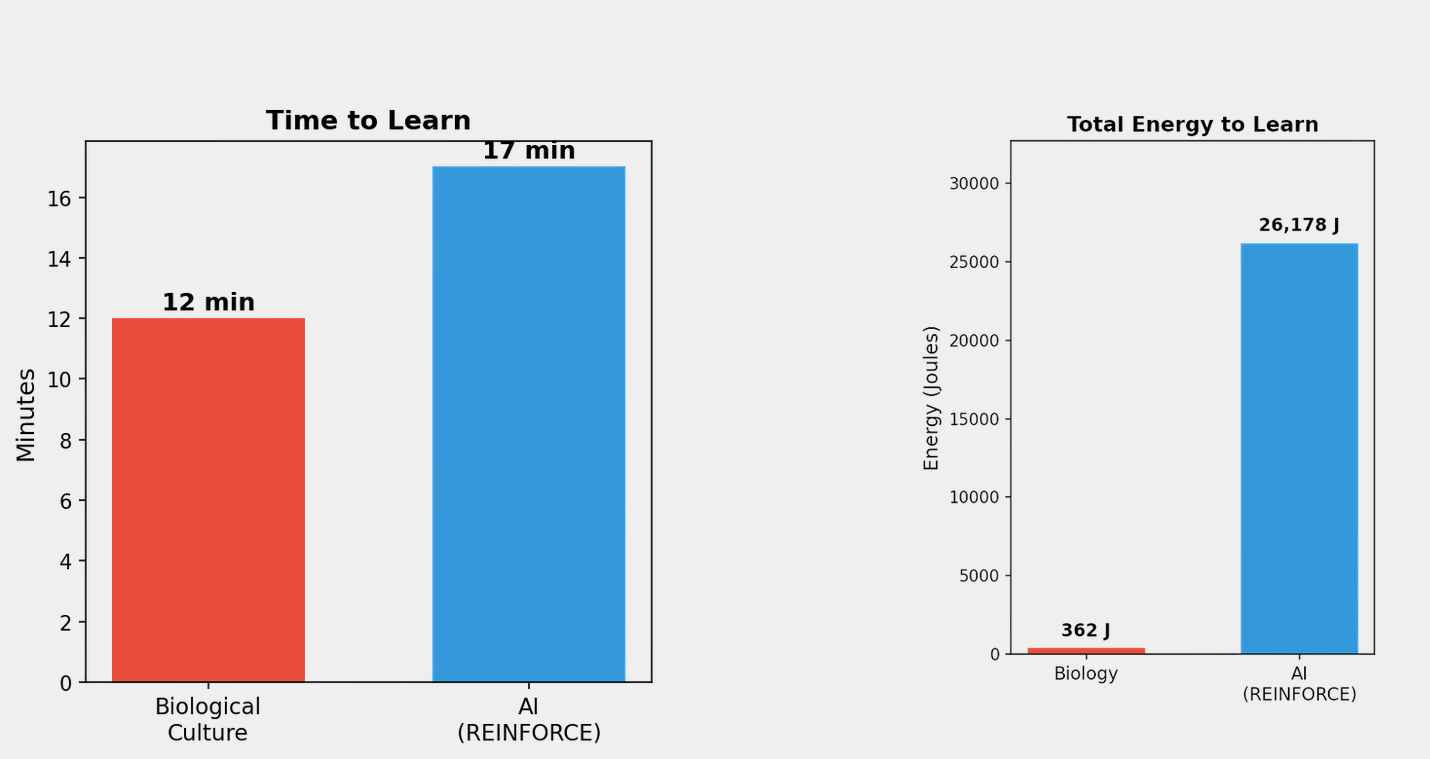
These plots compare the biological neuronal system against an AI model trained on the same Asteroid Dodger task under broadly similar task constraints. The comparison highlights both the time required to acquire effective control and the energetic overhead associated with learning.
The biological system exhibited measurable learning after approximately 6 minutes and reached peak task performance at approximately 12 minutes, whereas the AI baseline required approximately 17 minutes to reach task proficiency. Notably, the biological system operated under a more restricted task representation: it was not provided with the ship’s own position and instead had to infer successful control through interaction with the environment. The AI model, by comparison, was trained with a more explicit state description.
The energy gap was also substantial. The biological system required approximately 362 J to learn the task, compared with approximately 26,168 J for the AI baseline. Importantly, in the biological system this measured energy is not spent by the neurons themselves, but by the interface hardware used to stimulate, record, and decode neuronal activity. That means the dominant energy cost comes from the external control layer, not from the computational substrate.
Unlike conventional AI, where energy demand grows exponentially with model size, data, and task complexity, the biological system is not governed by the same compute-scaling behavior.
Conclusion:
These results show that biological neurons can learn a dynamic control task in a closed loop, and can do so more efficiently than an AI model in terms of time, data exposure, and energy.
The neuronal system learned the task faster, with substantially lower measured energy, despite operating with less explicit state information than the AI model. This makes the comparison notable not only as a demonstration of learning, but as evidence that biological computation offers a fundamentally different resource profile for training intelligent models.